
 A writer’s hubris is the conviction that when you’ve covered a topic, you’ve had your say. But new readers rarely have time or desire to plumb earlier work and, were they to try, much of what I wrote on the underpinnings of e-discovery and forensics was long ago stolen away like Persephone to a paywall-protected underworld, leaving this Demeter to mourn. So, I briefly return to a point that has never gained traction in the minds of the bar, viz. why producing in native file formats doesn’t require we give up cherished Bates numbering. Doug Austin, the Zeus of e-discovery bloggers, recently re-addressed the same topic in his estimable E-Discovery Daily. Call me a copycat, but I was here first.
A writer’s hubris is the conviction that when you’ve covered a topic, you’ve had your say. But new readers rarely have time or desire to plumb earlier work and, were they to try, much of what I wrote on the underpinnings of e-discovery and forensics was long ago stolen away like Persephone to a paywall-protected underworld, leaving this Demeter to mourn. So, I briefly return to a point that has never gained traction in the minds of the bar, viz. why producing in native file formats doesn’t require we give up cherished Bates numbering. Doug Austin, the Zeus of e-discovery bloggers, recently re-addressed the same topic in his estimable E-Discovery Daily. Call me a copycat, but I was here first.
As many times as I’ve written and spoken on the Native DeBates, I’ve never felt I nailed the topic. I’ve not succeeded in conveying the logic, ease and advantage of a bifurcated approach to Bates numbering and pagination. So, one more shot.
Start by imagining a world where, instead of just numbering pages, runaway enumeration demanded everyone number lines of text in each item produced in discovery. That’s not far-fetched considering that pleadings in California and deposition transcripts everywhere have long numbered lines. If I demanded that of you in discovery, wouldn’t you sensibly respond that it’s overkill and lawyers have managed just fine by numbering by page breaks instead?
Now that you’re thinking about the balance between enumeration and overkill, let’s set aside tradition and come at Bates numbering by design. Mark a fancy word: unitization. Everything is unitized: time in days and hours, buildings in square feet or meters, television in seasons and episodes, books in chapters and pages. Humans love to unitize stuff, and our units ofttimes grow from quaint and antiquated origins that we cling to because, well, uh, um, dammit, we’ve just always done it that way!
Recently, I had a tough time getting rid of perfectly nice file cabinets because they were sized to hold files fourteen inches wide. When I became a lawyer, every pleading had to be filed on fourteen-inch-long “legal size” paper, not the familiar eleven-inch letter paper. Later, courts abolished legal size pleadings and…poof…that venerable unit was history. Now, even the notion of filing paper with courts is a relic. Things changed because it was cheaper and more efficient to change. Standards do change and units do change, even in the staunchly stodgy corridors of Law.
Why did the letter-sized page become a worldwide standard unit for documents? It didn’t. In most places outside of the U.S. and Canada, standard paper sizes are based on surface area not dimensions. The “standard” European page size is called “A4” and measures 8.3” × 11.7” (not that most of the world measures in inches, but let’s not go there). Anyone old enough to remember a time when word-processed documents were printed on mechanical printers will remember that a document’s layout and pagination varied from printer-to-printer. There’s nothing magical or iconic about the letter size page as a unit of printed information; and less so as fewer information items flow from or onto paper manifestations. Spreadsheets aren’t paginated. Neither are e-mails, websites, PowerPoints, message threads, voicemail or video.
Once, nearly all written evidence was stored as paper documents. Now, nearly all written evidence items are blocks of data: files on disks and records in databases. The printed page is not an efficient or economical way to unitize electronically stored information (ESI). As well, enumeration of ESI by page numbers based upon conversion to a static image format is like measuring and delivering water as ice cubes or steam. You can do it, but you really shouldn’t.
I want ice in my drink and steam in my iron, but my principal consumption of water will be as liquid, its “native” form at room temperature. Accordingly, unitization should be based on the native form (e.g., gallons), not the occasional altered form (cubes or cubic feet) until and unless the change of form is necessitated by the usage.
The same logic holds true for ESI.
For items produced in discovery, the unitization that makes most sense is the native unitization, files. Word processed documents, presentations, spreadsheets, photos, videos and sound recordings all manifest as files in the ordinary course. We store them as files, collect them as files, process and enumerate them as files and hash them as files for deduplication and authentication. It only stands to reason that we produce and Bates number items as files.
We “affix” Bates numbers to files in the same way that we identify files in the ordinary course. That is, we name each file produced or withheld to reflect its Bates number. It’s a flexible method that comports with the longstanding practice of naming images of printed pages to mirror the Bates numbers embossed on those pages. Bates numbers can be prepended to file names, appended to them or simply replace the filename (as the original filename is always produced in an accompanying load file). Nothing is lost and, because filenames aren’t stored inside files, changing a file’s name in this way doesn’t alter the file’s content or hash value.
Native production won’t end the use of Bates numbers; it just adapts the numbering to the appropriate unitization.
Oddly, naming files to reflect Bates numbers is tough for some to grasp. Perhaps they imagine it’s done manually, though of course it occurs simply and automatically, adding no cost to the process. Most lawyers wonder how they will use Bates numbered files. The answer is you use Bates numbered files in the same manner as you use any ESI in electronic discovery; that is, you employ an application to view the contents of the file and the application displays the Bates number. Not the native Word or PowerPoint program, but one of the many tools purpose-built to allow lawyers to review and search ESI.
This isn’t manifestly clear to lawyers who have trouble distinguishing between how they will review ESI versus how they will present it as exhibits. That’s a costly confusion.
It’s unquestionably convenient to print ESI used as exhibits to paginated formats on those occasions when a clear record is facilitated by doing so. I’ve taken hundreds of depositions, argued tons of motions and tried loads of cases. Depositions, trials and hearings haven’t changed much over my 37 years at the Bar; so, I’m no stranger to the value of embossed Bates numbers when data is printed for presentation to a witness or tribunal.
The question isn’t whether there’s a need and place for Bates numbered static forms (i.e., paper and electronic printouts), but when should conversion occur, applied to which parts of a production, and importantly, who gets to decide and at what cost (measured in money, utility and completeness)?
Native production splits the process of Bates numbering. The producing party retains the right to assign the Bates number to the file produced. The right to add page numbers belongs to the party who prints the electronic evidence for use in a proceeding. The Bates number assigned by the producing party must be embossed on every page of the printout along with the page numbers. That way, the producing party can always relate a printed item to its source file. In turn, all parties can reference the printout by Bates number and page number in the conventional way lawyers cite to exhibits in proceedings. Yes, Virginia, there really is a Bates number and pagination method for native files.
You may ask, “Won’t that mean that different printouts could have different pagination? Won’t that be confusing?” It’s possible that slight variations in page breaks could occur if the same file is printed on different systems and printers. In theory, that could prompt confusion; but in practice, it’s not a problem. The record is perfectly clear with respect to any version used by a witness or presented to the Court. You can concoct a situation where it’s chaos, but the reality is that it works quite well.
The reason we never faced this presumptive confusion before e-discovery was because, if you used a document I’d produced to you in discovery, that document bore the Bates number I’d stamped on it. You were forced to use the pagination I’d assigned. You couldn’t print a version with different pagination because I hadn’t produced the electronic evidence to you; I’d produced a printout. That was convenient and acceptable back when the evidence and a printout were useful and complete in the same ways. However, ESI and printouts are not the same anymore. They aren’t useful in the same ways. They aren’t complete in the same ways. They don’t cost the same to use. Notwithstanding these differences, producing parties still claim the exclusive authority to assign pagination at the time of production. That is, they demand the power to impose the wrong form of unitization at the wrong point in the discovery process.
Let’s focus on cost. When I seek production of ESI in its native electronic forms, it’s because that’s the form in which the evidence is used in the ordinary course of business and the most complete, utile and economical form. It’s the form the witnesses used. It’s the authentic evidence.
Producing parties resist native production for reasons I’ve addressed and refuted in other posts and publications. They once fought native production of spreadsheets and presentations; but that was always a lost cause. Yet, we still skirmish over e-mail and word-processed documents. Producing parties assert that electronic printouts (so called “TIFF Plus” productions”) are “reasonably usable” alternatives to native forms. My experience is that they can be usable, but frequently are an inadequate substitute for the complete, utile native forms.
The debate over forms of production might be written off as so much navel gazing if there weren’t a massive economic penalty imposed on requesting parties forced to accept TIFF Plus productions. A TIFF Plus production is many times larger byte wise that the same production made natively. For most, the cost of loading and hosting electronically stored information is determined by the amount of data loaded, processed and hosted. Ten times more data byte wise costs ten times more to ingest and ten times more to access online, month after month. Ten times more is at the low end of the differential.
This is hard for lawyers to accept. Requesting parties seem oblivious to the huge TIFF Plus penalty they bear. When I teach e-discovery at the University of Texas School of Law or Georgetown Law Center, I task my students to independently explore the cost difference. They generate a native production set and a TIFF Plus set from the same collection, then apply market rate ingestion and hosting prices to each. The difference? Native production and hosting cost about $30,000.00 less for 150MB of data than the same data produced as TIFF images.
So, what do you do? Let me preface by telling you what producing parties don’t have to do. They don’t need to buy software, change workflows or study computer science to make this work. All the leading e-discovery software tools support the ability to name files to mirror Bates numbers. Their e-discovery service providers can do it with ease. Of course, service providers might not be thrilled by their reduced billings for ingestion and hosting, but those savings directly benefit your clients and, unlike the savings from, say, predictive coding, they don’t come out of lawyers’ pockets.
There are many easy ways to add Bates numbers and page numbers to files when you print them out. But here’s the most important takeaway: Lawyers customarily use just a fraction of items produced in discovery. All files are Bates numbered when produced; only that tiny fraction printed for use as exhibits must be paginated for making a record.
The bottom line: You needn’t give up Bates numbers to reap the savings and utility of native productions. It’s wrong to suggest, “You can’t Bates number native productions;” you absolutely can and, importantly, you don’t have to depart from the familiar ways you use evidence as exhibits.
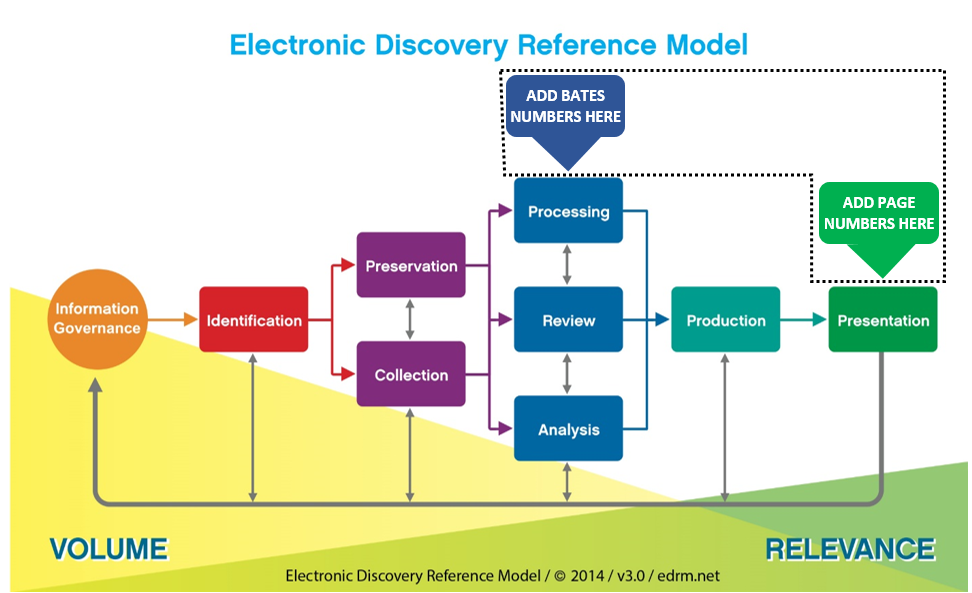
The graphic below incorporates the Electronic Discovery Reference Model and overlays pointers to the EDRM stages where Bates numbers and page numbers should be added. Producing parties add Bates numbers to filenames during processing; but by deferring conversion of ESI to paginated static images (e.g., printouts) until needed for presentation, only a small complement of production must be converted and degraded. Keeping the rest of the production in native forms ensures that the evidence retains its completeness, utility and economy (“just, speedy and inexpensive” being the goal). Application metadata and other content aren’t stripped away, and the size of the production won’t mushroom ten- or fifteen-fold, dramatically increasing the cost to load and host the production.

Doug Austin said:
Thanks for the shout-out, Craig! And indeed you were there first. I keep stifling my own desire to scream out loud “IT’S NOT THAT HARD!!” when trying to convince attorneys that native productions don’t preclude Bates numbering pages downstream. I love the EDRM diagram representation of the concept — maybe it will get through to lawyers better than what we’ve done before.
LikeLike
David Tobin said:
measuring and delivering water as ice cubes or steam. . . nice
LikeLike
K said:
Thank you, again, for your amazing wordsmith on a truly infuriating topic for us ediscovery practitioners!
LikeLike
Matthew said:
Excellent work, Craig. I guess the main thing that springs to mind is the form of the native file – ie a compound zip file, or even a Word document that has embedded files – and of course emails and their attachments – and also how to handle a JSON file from Slack.
My concern would be whether the other side inadvertently discloses embedded files that they aren’t aware of.
It does make sense, and I think for the core set of evidence for the trial, it would make sense for the parties to agree on the document set and one of the parties then render the set – in Australia the Plaintiff / Applicant has the role of managing the ‘Courtbook’.
LikeLike
craigball said:
Thank you, Matthew. I agree that finding the form best suited to the data can be challenging when the file is structured data (like a JSON file); but surely you aren’t suggesting that a TIFF rendering is a superior (or even a reasonable) form for production of a JSON? For that data, isn’t a “native” JSON file likely to be the best format for production (because it remains fielded and functional)?
I’m not daunted by a compound zip file because there’s a reasonable practice that’s grown up around how to handle immaterial container files in e-discovery. We process and produce the contents, not the container. Yes, production could be made at the compound container level if there were any advantage to doing so, but that’s not the custom and typically has no bearing on utility or completeness of the evidence. It would impact size/cost, and if a party deems that impact material and prejudicial (I wouldn’t), then the parties could talk it over and try to work something out (a novel idea, right?).
If an e-mail with attachments is relevant and not privileged, why wouldn’t we treat it as a logical unit (a “family” in e-discovery parlance) and produce the unit in a near-native form? Messages can then be threaded with ease and normalized in time, both tasks made more difficult (or impossible) to accomplish when rendered as TIFF Plus. Some may reply that you CAN thread and normalize in TIFF Plus IF the load file holds the right parts of the message header; but that’s something that rarely happens at all, and never happens well. Why should requesting parties have to hope they can put Humpty Dumpty together again? We’re not making omelets, so need not break eggs.
Finally–and you make my point so very well–the Word file. Lawyers using TIFF Plus address the potential for embedded content by destroying it rather than risk producing it inadvertently. In any other context, if a lawyer discarded relevant information subject to legal hold without looking at it, and then claimed the right to do so on the basis that it might be hurtful or privileged, we’d yell “foul!”
So, FOUL!!
It’s crucial to keep the scope of discovery and form of production separate in our thinking. Using native forms of production doesn’t broaden the scope of discovery. If a party is not entitled to production, the form for production doesn’t enlarge or diminish that entitlement. Items requiring redaction can and should be produced in forms that facilitate redaction, but we must be vigilant not to let the redaction tail wag the production dog. The items not requiring redaction should not be dumbed down to TIFF Plus, with the consequence that the bulk of the production becomes less functional and much more costly to ingest and host. Thanks for your comment.
LikeLike
Matthew said:
Thank you for the detailed response, Craig.
I should also have pointed out in my original comment that I agree with you, and that there would be very significant time and cost savings for everyone if we could get this right – ie that all sides to the dispute are not paying for the processing and hosting of the native file AND a rendered form of the file.
My worry about a JSON file is that its effectively a container of message threads – and you would have the conundrum of possibly having to unpick / unpack this to weed out what is within scope for the discovery.
In regards to compound files, as you point out, we have very well established practices in place for handling ‘unitization’ and ‘families’. On this point, what I was trying to get to was that popular processing tools may by default export native emails where the attachment has been permanently detached – which is of course easily addressed by changing a default setting.
What I’m struggling to articulate is a vague worry over whether the quality of production from another party could be ‘sloppier’ if it was in native form – ie where not as much care is taken as when you ‘had’ to render and stamp everything.
Presumably the next step in this journey would be Document IDs or Bates numbers and the accompanying load file.
LikeLike
craigball said:
I imagine the challenge of JSON isn’t much impacted by the form of production as (I hope) not even the most brain dead opponent would attempt to produce Slack content as TIFF images of unthreaded messages. The challenge of Slack and messaging generally is getting the vendors to build the interface to the content instead of the lazy approach of trying to deal with messages as email. Here. I must steal from American architect Louis Sullivan and say, “Form follows function.” I’m open to almost any form that preserves functionality.
Yes, it could be sloppier—never underestimate the power of lawyers to screw things up—but the incentives to be competent better align with the risk so as to promote diligence, not immunize obstruction.
LikeLike
Jordan Gratrix said:
Craig, I agree absolutely with your argument that documents produced are far more voluminous than documents used as evidence, and therefore the distinction between when pagination is necessary and justified by cost, or even by ability to efficiently review by the requesting party.
I do take issue with the assertion that TIFF+ productions require ingestion at 10x rates in addition to hosting at 10x rates (x as a multiple of native production sizes).
If you are paying for ingestion costs on inbound productions in TIFF+ formats, you are working with a vendor that is fleecing you. Those productions should incur at most an hourly fee for a specialist to map data fields, and then the per /GB charge most vendors apply for periodic hosting billing. There is no processing necessary on a TIFF+ production delivered iwith appropriate load files for the intended platform, all of which should have been discussed and agreed upon prior to the first production.
LikeLike
craigball said:
Thank you for your comment. I take it as a wake up call to those who don’t negotiate rates based on the peculiar nature of the data to be ingested and hosted; but if we are frank in our assessment of the marketplace, isn’t that most of those on the receiving end of a TIFF Plus production? If they’ve let themselves be (insert inoffensive euphemism for ‘prison raped’) by TIFF Plus, why would we imagine they possess the snap to not be (repeat euphemism) once more by their service providers? Of course, I going for the cheap laugh there, but shouldn’t something be cheap in e-discovery?
Maybe some vendors are waiving “processing” costs for ingestion and charging nothing more than a couple of technical hours; but, can we put ANY names to those great Samaritans? I’m skeptical, but will keep my eyes peeled for halos at ILTA.
Worse, there aren’t any processing economies gained from a properly-constructed production set. And, in the end, they still gig us every month with the bloated hosting charges occasioned by the morbidly obese TIFF images.
When do the first set of load files work? 😉
LikeLike
Wade P. said:
Craig, well said again and I completely agree with your position. In addition to your excellent points, I believe we live in a 3-dimensional world, whereas TIFF was developed for a 2-dimensional world, i.e., typewriters, mimeograph machines, and faxes. Practically all native files these days are not “flat” and do not represent themselves well in the 30 year old, designed for slow analog phone lines, B&W TIFF format. The richness of today’s file formats requires a serious re-thinking. Thanks for re-energizing the conversation. It’s about time for a change.
LikeLike
craigball said:
I love that 3D versus 2D metaphor!
LikeLike
John Trickey said:
Good article Craig. I think we all cringe…Well, if only we could get to native productions as a standard but not holding much hope. Some vendors, and I am one, are forward thinking and looking at this industry as a storage only business whereas no billing for ingestion, analytics and productions or all of the other button pushing things. Only a low active hosting rate based on data footprint and the higher the footprint the lower the price with users and pm time included.
IaaS and SaaS should change the pricing models… Saas licenses, computing power and storage is cheap so why shouldn’t the clients benefit from this. Well, I think the old models of billing aren’t changing much as everyone is clinging to their higher margins and carry a large overhead or have many people to answer to for change to happen.
LikeLike
craigball said:
Your vision of the future is spot on, and likely dominated by O365. Kiss much of the rest of the “industry” goodbye.
Not to state what you know but for the benefit of some who might read the comments, we shouldn’t have to “get to native.” We START with native a/k/a the authentic evidence. Instead, we need to stop running away from data as used in the ordinary course and call out TIFF Plus conversion for the abuse and intentional spoliation it is.
The issue isn’t going to go away because, however we localize in the Cloud and “bake in” indexing and analytics, evidence must nevertheless be produced in some utile, practical form sought by the requesting party. The one thing that doesn’t change is the need for suitable and economical forms of production.
You may be right to consider this a lost cause as long as corporations call the tune. What’s the phrase? “The only thing necessary for the triumph of evil is for good men to do nothing.”
LikeLike
Pingback: Atkinson-Baker | Who Says You Can’t Bates Number Native Productions?
Bharat Chovatiya said:
Great article! Thank you for writing it and staying on the top of promoting native productions.
Disclosure: I lead a company specialized in native file mass redactions.
Here are my thoughts on why native files productions are not mainstream productions, and how it will be in the future.
The image format productions are time-consuming, expensive and often technically challenging. However, it remained widely accepted for so long for three major reasons.
1. There are many reliable applications to display TIF images in read-only format, but none that can display the native files as read-only, disabling user-initiated changes, display all the parts of the native files properly, and are programmable. PDF is the closest to TIF in this regard. To make native review and productions widely adopted, we need a system that can display native files properly, protects them against accidental alterations, warn about the possible presence of invisible content, and allow the users to look beneath the top layer.
2. The TIF file format is static for more than two decades, with no changes in the file format. Also, it always displays the same information across a variety of operating system and image display applications. What you see is always what you get and what everybody else sees. That’s not the case with any native formats because of all they constantly change. Moreover, a file doesn’t always display the same across applications, even when created by the same company. For example, a Word document created in MS word 2013 Windows version doesn’t always display the information same was in Mac version of MS Word 2013 because certain features are available in Windows version of the application, but not in the Mac OS version. This creates a trust issue. While reviewers can say with certainty that they reviewed all the content in TIF, they can’t say so for the native files.
3. Redactions in TIF format is unlikely to be legally challenged due to its widespread acceptance by judicial bodies across the world. However, when it comes to native redactions, many clients feel it unsafe because it is not legally challenged and defended. Believe it or not, we keep frequently hearing the question of whether or not our native redaction technology is legally challenged. So far, the answer is “No”. Many prospects then choose TIF productions. The point is that once the native file redactions get legal defense or acceptance, it will quickly be accepted by the other parties.
With no sign in a slowdown of legal discovery cost rising, it is a matter of time when the native review-redaction-production becomes mainstream. The market is ripped for the change. Native redactions and productions have already started taking a leap forward and it is going to be a major paradigm shift in the near future.
LikeLike