
 In his keynote speech at the Zapproved Preservation Excellence Conference in Portland, Dr. Tony Salvador of Intel compared the “encores” of performers today to those of performers a century ago. “Encore,” Salvador noted, is French for “again;” yet, we use it to mean “more.” Today, performers brought back by applause don’t repeat their performance; they play a different song.
In his keynote speech at the Zapproved Preservation Excellence Conference in Portland, Dr. Tony Salvador of Intel compared the “encores” of performers today to those of performers a century ago. “Encore,” Salvador noted, is French for “again;” yet, we use it to mean “more.” Today, performers brought back by applause don’t repeat their performance; they play a different song.
But for hundreds of years, the encore was an unpredictable, spontaneous eruption. Stirred by a brilliant aria in the midst of a performance, members of the audience would leap to their feet in applause, shouting, “ENCORE! ENCORE!” The singer and musicians were compelled to stop and perform the same song AGAIN. This might happen over and over, until the rapture was so fixed in the listeners’ minds they’d relent and let the performance continue.
The audiences of the 18th and 19th centuries demanded repetition of what they heard because there was no technology to reproduce it. Once Edison made sound stick to a cylinder, the mid-show encore disappeared, and the race to record everything began.
The natural world is an analog world. The signals to our senses vary continuously over time, experienced as waves of light, vibration or other stimuli. Much of the last century was devoted to recording analogs of these analogs; that is, preserving the waves of the natural world as waves that could be impressed upon tinfoil, wax and vinyl, as areas of transparency and opacity on photographic film or as regions of varying magnetic intensity on tape.
Then, late in the 20th century, we learned to mimic analog information using the rapid “on” and “off” of digital data, and devoted the last quarter of the century to converting our vast collection of analog recordings to digital forms. ENCORE! ENCORE! (But this time, do it in ones and zeroes, okay?). It was my generation’s take on converting manuscripts to movable type in the middle ages.
What distinguishes the 21st century from all before it is that information is now born digitally. Information is processed to digital forms without intervening analog storage, and much information has no analog existence at all.
Despite its daunting complexity, all digital content—photos, music, documents, spreadsheets, databases, social media and communications—exists in one simple and mind‐boggling form: encoded as an unbroken string of ones and zeroes. That’s astonishing, but what should astound you more is that there are no pages, paragraphs, spaces or markers of any kind to define the data stream. That is, the history, knowledge and creativity of humankind have been reduced to two different states (on/off…one/zero) in an unbroken, featureless expanse. Moreover, it’s a data stream that carries not only the information we store but also all of the instructions needed to make sense of the data. The data stream holds all of the information about the data required to play it, display it, transmit it or otherwise put it to work. It’s a reductive feat that’ll make your head spin…or at least make you want to buy a computer scientist a beer.
This post touches on how digital encoding works because, whatever your interest in e-discovery or forensics, you can only get so far ascribing it all to magic. After that, it helps to understand encoding.
When I teach this stuff, I challenge my audience to concoct a means to write English using just consonants, no vowels. They quickly conclude that they can do so by substituting obscure groups of consonants for vowels. Then, I take away a bunch of consonants and challenge them to do it again. Their epiphany is that, if you employ longer sequences to convey information, it requires fewer discrete symbols to express it. So, you can, e.g., encode intelligible English prose without any vowels and just a handful of consonants–or maybe even write everything in ones and zeroes alone.
 I seek to forge a connection in my students’ minds between numbers and alphabets. At right is a picture of Radio Orphan Annie’s Secret Society Magic Decoder Ring. The folks at Ovaltine used to send these rings to young radio listeners in the mid-1930s. The Magic Decoder Ring employed a simple numeric substitution cipher to allow kids to encode and decode secret messages. Armed with their decoder ring and the message key (“Psst! X=1 today”), they’d rotate the number ring to position the numeric key alongside its associated letter, and the rest of the cipher could be decoded. 11-7-12 6-12?
I seek to forge a connection in my students’ minds between numbers and alphabets. At right is a picture of Radio Orphan Annie’s Secret Society Magic Decoder Ring. The folks at Ovaltine used to send these rings to young radio listeners in the mid-1930s. The Magic Decoder Ring employed a simple numeric substitution cipher to allow kids to encode and decode secret messages. Armed with their decoder ring and the message key (“Psst! X=1 today”), they’d rotate the number ring to position the numeric key alongside its associated letter, and the rest of the cipher could be decoded. 11-7-12 6-12?
Using a standard encoding scheme, it’s easy to express language as numbers. Because the Latin alphabet consists of only 26 letters, you don’t need many numbers to stand in for uppercase letters, lowercase letters, zero through nine, common punctuation marks and some machine instructions like “line feed” and “bell.” For decades, the most common encoding scheme was the American Standard Code for Information Interchange, or ASCII (pronounced ask-key). ASCII mapped the alphabet and other characters to 128 numeric values (000-127 because computers count from zero), hence: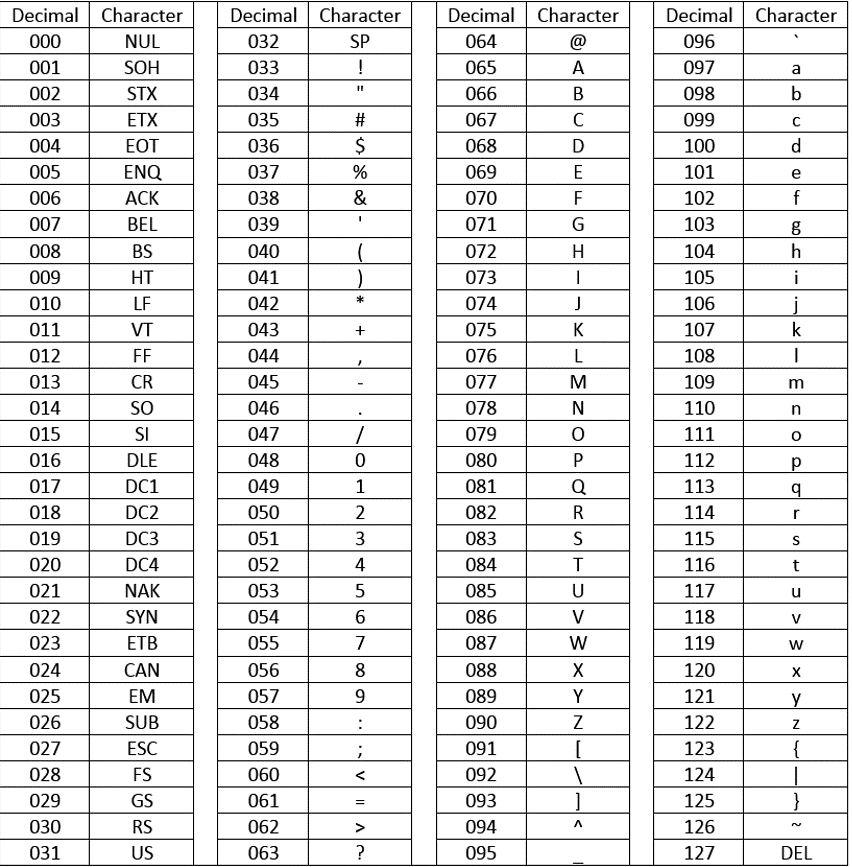
Many encoding schemes succeeded ASCII, including those designed for languages with many more characters and pictograms, like Chinese, Japanese and Korean. Yet, even as the most common encodings and code pages have morphed, the fundamentals of character encoding haven’t changed a bit.
The last step in mastering the rudiments of encoding is learning to express any number in ones and zeroes. This is “binary” or “base 2” notation, and it’s the hardest part; so, let’s break for some good old fashioned encoding humor:
On his first day in prison, a young inmate is brought to the mess hall and put at a table of hardened cons. One old timer stands and yells, “37!” The room erupts in laughter. Another stands and yells, “23!” Again, everyone laughs like crazy. Mystified, the new arrival asks what’s going on. “Well,” an old con says, “Most of us have been here so long we’ve heard every joke a million times. Now, we number ‘em and just call out the numbers.” The newbie brightens and says, “I love jokes. Gimme the number of a good one.” “Okay,” says the old timer. “Everybody likes old #57. It always slays ‘em.” The new guy stands, waits for the laughter to die down, and yells, “57!” Stony silence. Every inmate just turns and stares at him. The kid sits down and asks, “What happened?” The old con shrugs and says, “Sorry kid. Some guys just can’t tell a joke.”
It’s encoding humor. What did you expect?
Binary
Since we need 128 numeric values to encode data in ASCII and tens of thousands of values for other encoding schemes, we need a way to express big numbers using just ones and zeros.
This might be an opportune time to ask, “Why just ones and zeroes?”
It’s because digital computers are built from countless microscopic, electronic on/off switches—billions, trillions of them etched on tiny wafers of silicon. Because these switches have only two ‘positions’—“on” and “off”—they perform their magic using just two values or “states” that we label “one” and “zero.” In computing parlance, a value that can be one or zero is called a binary digit or a “bit.” Bits are the most basic units of information in computing and digital communications.
If you want to count higher than one using bits, you need a way to write bigger numbers using just ones and zeroes. You got to use “binary” or “base 2” notation.
Running the Bases
When we were children starting to count, we had to learn the decimal system. We had to think about what numbers meant. When our first grader selves tackled a big number like 9,465, we were acutely aware that each digit represented a decimal multiple. The nine was in the thousands place, the four in the hundreds, the six in the tens place and so on. We might even have parsed 9,465 as: (9 x 1000) + (4 x 100) + (6 x 10) + (5 x 1).
But soon, it became second nature to us. We’d unconsciously process 9,465 as nine thousand four hundred sixty-five. Later, we learned about exponents as powers of ten and now saw 9,465 as: (9 x 103) + (4 x 102) + (6 x 101) + (5 x 100). This was exponential or “base ten” notation.
Mankind probably used base ten to count because we evolved with ten fingers. But, had we slithered from the primordial ooze with eight or twelve digits, we’d have gotten on just fine using a base eight or base twelve number system. It wouldn’t matter because any number–and consequently any data–can be expressed using any base number system. So, it happens that computers use base two/binary notation, and computer programmers are partial to base sixteen or “hexadecimal” notation. It’s all just counting.
Unlike the decimal system, where any number is represented by some combination of ten possible digits (0-9), each bit has only two possible values: zero or one. This is not as limiting as you’d expect when you consider that a digital circuit—again, an unfathomably complex array of switches—hasn’t got any fingers to count on, but digital circuits are very good and very fast at being “on” or “off.”
 In the binary system, each bit signifies the value of a power of two. Moving from right to left, each bit represents the value of increasing powers of 2, standing in for two, four, eight, sixteen, thirty-two, sixty-four and so on. That makes counting in binary pretty easy. How do you figure out the value of the binary number 10101? You do it in the same way we did it above for 9,465, but you use a base of 2 instead of a base of 10. Hence: (1 x 24) + (0 x 23) + (1 x 22) + (0 x 21) + (1 x 20) = 16 + 0 + 4 + 0 + 1 = 21. From zero to 21, decimal and binary equivalents look like the table at right.
In the binary system, each bit signifies the value of a power of two. Moving from right to left, each bit represents the value of increasing powers of 2, standing in for two, four, eight, sixteen, thirty-two, sixty-four and so on. That makes counting in binary pretty easy. How do you figure out the value of the binary number 10101? You do it in the same way we did it above for 9,465, but you use a base of 2 instead of a base of 10. Hence: (1 x 24) + (0 x 23) + (1 x 22) + (0 x 21) + (1 x 20) = 16 + 0 + 4 + 0 + 1 = 21. From zero to 21, decimal and binary equivalents look like the table at right.
Bytes
A byte is a sequence or “string” of eight bits. The biggest number that can be stored as one byte of information is 11111111, equal to 255 in the decimal system. The smallest number is zero or 00000000. Thus, there are 256 different numbers that can be stored as one byte of information. So, what do you do if you need to store a number larger than 256? Simple! You use a second byte. This affords you all the combinations that can be achieved with 16 bits, being the product of all the variations of the first byte and all of the second byte (256 x 256 or 65,536). So, using bytes to express values, any number that is greater than 256 needs at least two bytes to be expressed (called a “word” in geek speak), and any number above 65,536 requires at least three bytes, and so on. A value greater than 16,777,216 (2563 or 224) needs four bytes (called a “long word”) and so on.
Let’s try it: Suppose we want to represent the number 51,975. It’s 1100101100000111, viz:
 Why is an eight-bit sequence the fundamental building block of computing? It just sort of happened that way. In this time of cheap memory, expansive storage and lightning-fast processors, it’s easy to forget how scarce and costly these resources were at the dawn of the computing era. Seven bits (with a leading bit reserved) was basically the smallest block of data that would suffice to represent the minimum complement of alphabetic characters, decimal digits, punctuation and control instructions needed by the pioneers in computer engineering. It was, in another sense, about all the data early processors could chew on at a time, perhaps explaining the name “byte” coined by IBM scientist, Dr. Werner Buchholz, in 1956.
Why is an eight-bit sequence the fundamental building block of computing? It just sort of happened that way. In this time of cheap memory, expansive storage and lightning-fast processors, it’s easy to forget how scarce and costly these resources were at the dawn of the computing era. Seven bits (with a leading bit reserved) was basically the smallest block of data that would suffice to represent the minimum complement of alphabetic characters, decimal digits, punctuation and control instructions needed by the pioneers in computer engineering. It was, in another sense, about all the data early processors could chew on at a time, perhaps explaining the name “byte” coined by IBM scientist, Dr. Werner Buchholz, in 1956.
Bits to Bytes to ASCII
Using a single byte, we now have a way to notate up to 256 unique values, and remember, we only needed half that number to store the 128 basic ASCII alphabet. So, in the table below, I’ve substituted binary byte values for their decimal equivalents in the previous ASCII table and “E-Discovery” can now be written in a binary ASCII sequence as:
010001010010110101000100011010010111001101100011
0110111101110110011001010111001001111001

So there you have it: a bare bones explanation of encoding. Why care? Encoding issues touch every corner of e-discovery and frequently lie at the heart of headaches in identification, indexing, deduplication, search, advanced analytics, load file generation and even imaging and printing of documents. Understanding encoding is crucial to gaining e-discovery competence and confidence; and that, dear reader, is no reductio ad absurdum!
.
.
.
.

Celia C. Elwell, RP said:
Reblogged this on The Researching Paralegal and commented:
Craig Ball makes it sound so easy. -CCE
LikeLike
Bill Hamilton said:
Craig,
Thank you for your wonderful tour of the foundations of our binary ecosystem. To many lawyers digital files (“documents”) are hidden “ghosts in the machine” that magically appear and disappear on the screens of our proliferating devices. The current legitimacy crisis of our civil justice system will only be resolved by prompt, inexpensive, and equal access to meaningful information distilled from our data tsunami. However, this predicate to a fair and just dispute resolution process requires competing lawyers to understand the foundations of contemporary digital information. The alternative is to be swamped in the cascading deluge of digital data in its multitude of formats and flavors and to succumb to a hobbled, meaningless litigation processes. Without really understanding data, we will continue to shout at one another at Rule 26(f) conferences with ossified words of obscure connotative meaning detached from any denotative value. Is eDiscovery education up to the task?
LikeLike
Gerard Britton said:
Craig,
My oldest, the computer engineer, assures me that we are quickly approaching the quantum computing stage. Goodbye bit, hello qubit. I guess it’s best get used to confidence intervals….
LikeLike