
Tags
Disclaimer: I serve as General Counsel of EDRM, but this message is mine alone: Nothing that follows speaks for EDRM or its leadership.
I recently received a marketing email that contained this gem: Organizations are “asking if EDRM is structurally prepared for investigations.”
Short answer: Yes. Obviously. Because the EDRM was never a structure to begin with.
That’s not a knock. That’s the point.
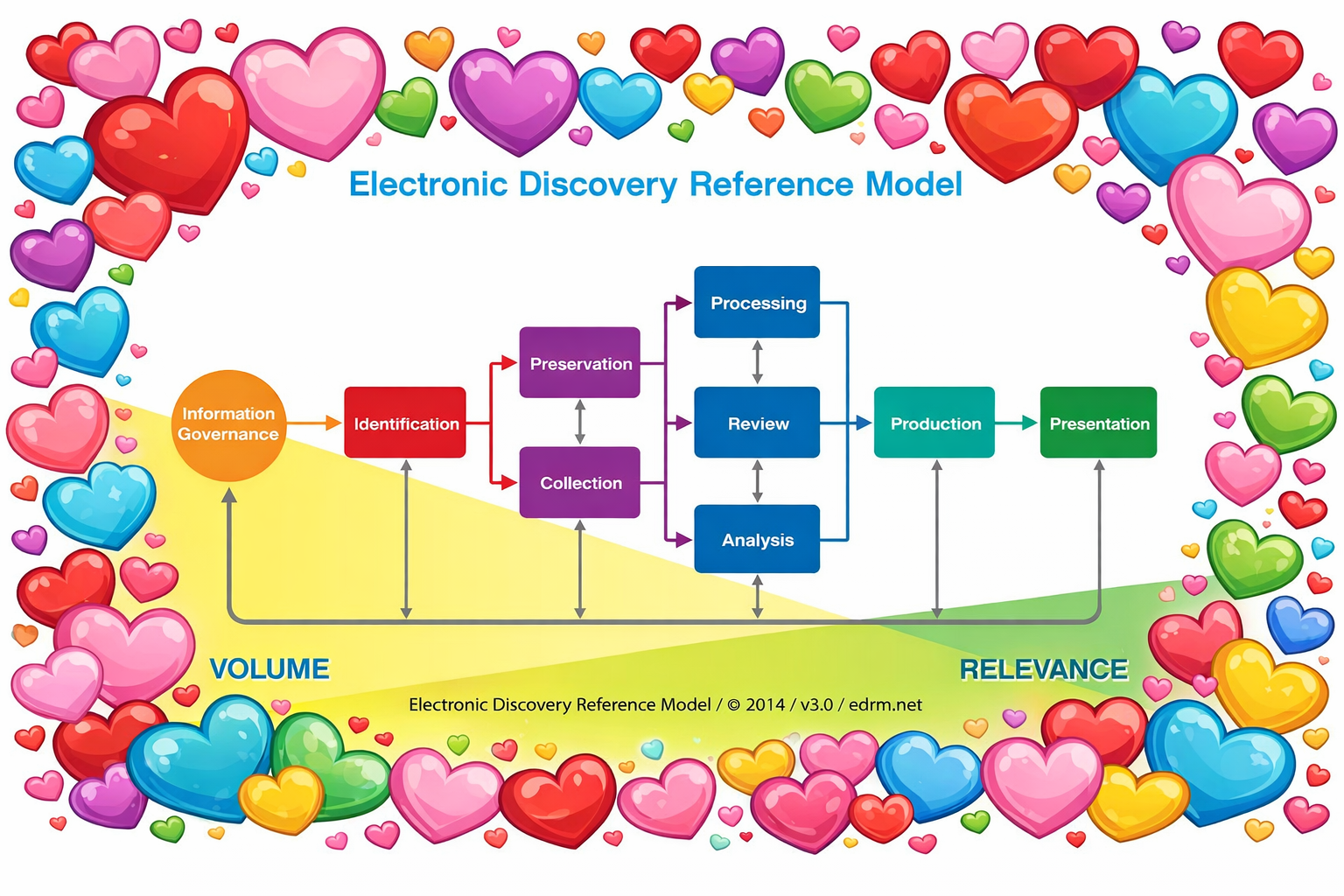
The Electronic Discovery Reference Model is–wait for it–a reference model—not a workflow, not a platform architecture, not an operational blueprint. A reference model is a conceptual framework that identifies the principal stages and relationships in a process. It doesn’t tell you how to do something; it maps what needs doing. Think of it as a compass, not a GPS turn-by-turn. It orients you. It doesn’t drive for you, and it ain’t broke.
The EDRM diagram—that familiar left-to-right ribbon of stages from Information Governance through Presentation—has never pretended otherwise. It emerged before we had a framework to talk sensibly about the conceptual components of exchanging ESI as evidence. It has always depicted a reference arc, not a rigid assembly line. Wise practitioners always understood that the stages overlap, iterate, and telescope depending on the matter. You don’t march from Identification to Collection to Processing like soldiers in formation. You loop, you backtrack, you run stages in parallel, recurse and iterate. The model accommodates all of that because it describes the territory, not the trail. You want to merge or collapse several stages in your preferred workflow? Go for it! The EDRM doesn’t proscribe that, just as cramming several stages into a single super-stage doesn’t do away with the need to complete the tasks the sub-stages describe.
So when someone asks whether EDRM is “structurally prepared for investigations,” the premise is the problem. They’re evaluating a map by asking whether it can carry luggage.
The shift toward “governed internal workflows where legal, security, and compliance operate from a shared investigation infrastructure” is a legitimate operational development. Organizations should be thinking about unified investigation infrastructure. But that’s a workflow conversation—a conversation about tooling, governance, access controls, and process design. It is emphatically not a conversation that requires or benefits from declaring the EDRM obsolete or unprepared.
The EDRM doesn’t compete with your investigation workflow. It informs it. The moment you need to think about what data sources to identify, how to preserve without spoliation risk, how to collect defensibly, how to process for review, how to analyze and produce—there’s the EDRM, as useful and orienting as it has ever been.
What the EDRM can’t do—and was never meant to do—is be your ticketing system, your case management platform, or your chain-of-custody log. If your investigation workflow is broken, that’s not the EDRM’s fault for failing to be software. It’s a planning failure for expecting a reference model to do a workflow’s job.
The schematic is fine (circa 2014). The thinking around it sometimes isn’t.
Use the EDRM for what it is: a durable, vendor-neutral conceptual foundation that helps you ask the right questions in the right sequence. Then build or buy whatever workflow infrastructure serves your organization’s needs. The two aren’t in tension unless you insist on making them so.

