

I read a couple of good articles on the e-discovery implications of the Mueller report and tweeted,
“The Mueller report underscores why image+ productions are ridiculous. Compare the OCR to the true text. It’s a mess, so search is off. Image files many times larger than the native, ergo much more costly to load, store, host, transmit. BTW: YES, you CAN redact a Word file. It’s XML!”
This bears fleshing out, and I want to do it by sharing a simple trick enabling you to peer inside the raw guts of a Microsoft Word file and understand why native redaction isn’t the pipe dream some try to make it. But first, let’s unpack the jargon.
“Image+” or “TIFF+” productions refer to the common practice of fixing the content of a document by printing the file to a static image format like TIFF or PDF. I use “fixing” in the sense of making something permanent, but it’s also accurate to use it the way we speak of “fixing” a cat; that is, cutting its balls off.
The “plus” in TIFF+ refers to the need to supply the native file’s searchable text and application metadata in ancillary load files to accompany the page images. That is, rather than supply the evidence, producing parties degrade it to a deconstructed “kit” version of the evidence that requesting parties must load into review platforms to restore a crude level of searchability. This enables producing parties to suppress content (like embedded comments, speaker notes and changes in text documents) and much of the application metadata of the original. It also neuters the evidence. It’s no longer functional in the programs that created it, like Word, PowerPoint or Excel.
I’ve written extensively about this elsewhere (e.g., Lawyers’ Guide to Forms of Production ), and I try to present the pros and cons of TIFF+, notwithstanding my belief that the cons decidedly outweigh the pros. It largely comes down to Bates numbers and disagreement about how and when those fetishistic Bates identifiers should be added to evidence and at what absurd cost.
TIFF+ enables producing parties to sidestep their obligation to review unprinted information for responsiveness and privilege. Instead, they silently make that content disappear like a “fixed” cat’s testicles. To be fair, most lawyers know so little about ESI processing that they are blissfully unaware it’s happening, so they deny it with genuine equanimity. When you force them to acknowledge the spoliation, they fall back on claiming that, whatever they excised and didn’t review wouldn’t have been worth the trouble of reviewing or producing. Genius, right?
Apart from what’s missing from the dumbed-down data, the big objection I offer to TIFF over native productions is the huge size difference between them. TIFF productions are much, much fatter. Though information and utility has been stripped from the images, the degraded set is nonetheless many times larger (measured in bytes) than the native originals.
Because most e-discovery service providers price their wares by the gigabyte volume going into, onto and out of their systems, bigger files mean bigger bills. Much bigger files mean…well, you get it.
Perhaps you’re thinking, “Craig, you sad, sad Cassandra; how much bigger can these image sets be than their native counterparts?” Would ten times bigger surprise you? Well, then surprise! But, they’re usually more than ten times larger. It’s not a one-off rip-off either. Most hosted platforms charge you for the fatter file volume every month. Over, and over, and over again.
Sucker.
But, back to the Mueller Report. Native electronic text files are inherently electronically text searchable. There are a few exceptions to that, but they don’t belie the essential truth of the inherent electronic searchability of native formats. Now, if you print those electronic files to TIFF images or paper, that strips away all text searchability. It’s gone.
Somehow, we must get it back (if only because the Federal Rules of Civil Procedure specifically caution against significantly degrading searchability) Fed.R.Civ.P. 34, 2006 Advisory Committee Note.
Most often, parties restore searchability by extracting textual content from the native files and handing it over in a load file. Load files are key components of that “some assembly required” kit approach I spoke of. There are lots of problems that flow from producing extracted text in load files; yet, the incidence of malformed content is small. But, when you print native files to paper (as happened with the Mueller report) and you don’t extract text from the native files, your only means of adding back searchability is a miraculous-but-error-prone technology called OCR for Optical Character Recognition.
The best that may be said of using OCR-generated text to restore searchability is that it’s better than nothing. Or maybe it’s not. Falsely believing that your electronic search is effective may be worse than knowing it’s not. Lots of lousy load files change hands daily.
You know what people (especially lawyers) don’t do when they substitute OCR text or extracted text for native text? They don’t look at the swapped text. They load it to their review platforms and proceed as if all’s right with the world.
But it’s not. With extracted text, you’re generally okay; but even then, it’s astounding how much is incomplete or malformed. Yes, even with extracted text, folks. Look at the load files if you don’t believe me. That’s the first takeaway: you’ve got to look at these files to appreciate how bad they can be.
But with OCR, whoa Nelly! Even the best OCR tools generate malformed text when run against clean, well-aligned pages. Skew the page a bit (auto feeders do it all the time), add redactions or marginalia–maybe some highlighting, handwriting or graphics–and you can count on ugly load files that are going to screw up search. How do I know? Simple, I LOOK at the data. I don’t have to look long to find errors.
How many search errors are too many when the matter is important? How many of us handle matters unimportant to our clients?
Why Native Redaction is No Pipe Dream
![]() Now, for some nerdy fun. Have you ever wondered why Word and other Microsoft Office files got new file extensions a dozen years ago (DOC became DOCX, PPT became PPTX, XLS to XLSX and so on)? No, of course you haven’t wondered because you have a rich, full life. So, I’ll tell you.
Now, for some nerdy fun. Have you ever wondered why Word and other Microsoft Office files got new file extensions a dozen years ago (DOC became DOCX, PPT became PPTX, XLS to XLSX and so on)? No, of course you haven’t wondered because you have a rich, full life. So, I’ll tell you.
Before Office 2006, Office file formats used a proprietary binary format. Starting with Office 2007, Microsoft changed the default file formats for Office documents to an open format, compressed structure called Office Open XML. XML is short for Extensible Markup Language. A Markup Language is a way of annotating the contents of text documents with formatting instructions and notes called tags or markup instructions such that the text and the annotations are readily distinguishable from one-another.
Lawyers old enough to remember the word processing program WordPerfect will fondly recall its ability to Reveal Codes and display bracketed formatting instructions. Seeing the formatting codes made it simple to alter or delete them. The tags in an XML-formatted document are also bracketed, and XML is termed “extensible” because users can create custom tags.
So, when Microsoft shifted Word, Excel and PowerPoint to open file formats, the Office programs stored files in XML, not binary formats–hence the “X” added to the file’s extension. Another key change was to integrate lossless compression such that Office programs compressed the XML using the Zip compression algorithm, substantially reducing file sizes compared to the previous binary formats.
If you were to look at the contents of an Office Open XML file as it’s stored natively, you’d see that the file begins with the initials PK (in ASCII; it’s 504B in hexadecimal).
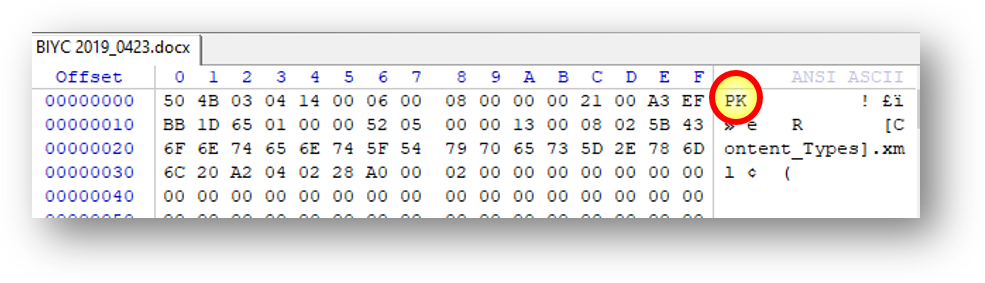
That PK at the start of the file serves an important purpose. It’s the file’s binary header signature. In computing, a file’s header refers to data occurring at or near the start of the file that serves to identify the type of data contained in the file and may also furnish information about the file’s length, structure or other characteristics. That PK means that the file data that follows is encoded and compressed with Zip compression. In other words, as a file header,” PK” signals to the operating system that the data will only make sense if it is interpreted as Zip-compressed content.
Why PK? Because the fellow who came up with the Zip compression algorithm was named Phil Katz! Katz insured his place in history by using his initials as the binary header signature for Zip files.
Because the file’s extension is .docx, the computer’s operating system will launch Word to open it and Word will decompress the file’s contents, load the XML within and display it in the familiar Word interface. The user doesn’t see the XML.
But you can peek at the xml contents if you trick the operating system to decompress the file instead of letting Word do it. Simply make a copy of a Word file you want to explore and change (i.e., rename) the copy’s extension from .docx to .zip. Now, open the renamed copy. Your operating system should decompress the file using the default compression program and allow you see the guts of your Word document.
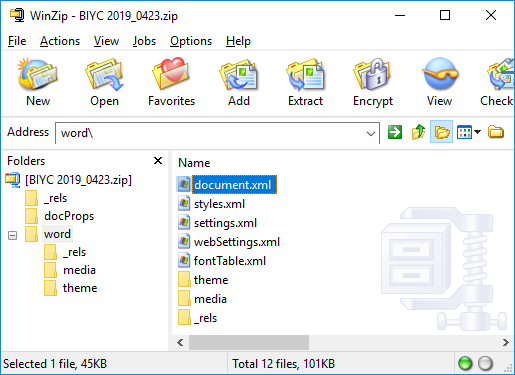
Example: As the figure below shows, my Word file for this post, called BIYC 2019_0423, was renamed with a Zip file extension and opened in WinZip to decompress the contents. You can now see all the pieces that make up the Word file. The formatted text of the file is stored in XML in a subfile called “document.xml.”
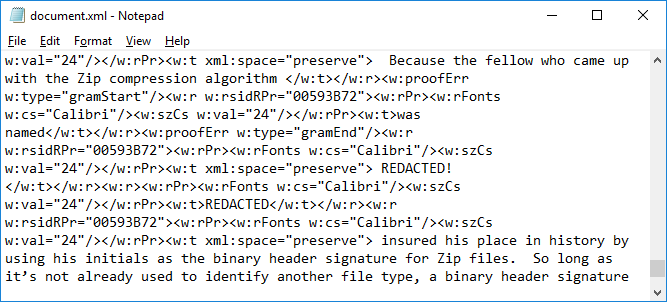
The next figure shows a snippet of what the contents of document.xml look like opened in Notepad. I’ve replaced the words “Phil Katz” and “Katz” with the text “REDACTED.” When I saved the redacted file and updated the Zip archive, the file was properly redacted, yet the altered file remained in its native Word format at all times and the contents sought to be redacted were thoroughly excised.
My point is not, “Hey, do this yourself.” Not at all. My sole point is that the Open XML structure of Microsoft Office files makes it feasible to access and reliably alter the contents of these native formats. That’s been true for a dozen years. Native redaction is real. For Word, Excel and PowerPoint and for PDF files, too. You don’t have to take my word for it. You can run your own test and make up your own mind.
Isn’t it time we started demanding tools to redact natively instead of clinging to the idiotic, error-prone and labor-intensive ways we do it? If native redaction tools are already out there, when will we smarten up enough to use and trust them? Mueller? Mueller?

Fabrice Mous said:
Hi Craig,
Very interesting and entertaining article and I love it how you throw down the gauntlet on native redaction. Interesting to see more discussion on this idea.
Thanks for writing and sharing.
Regards,
Fabrice
LikeLike
Tree said:
Those bates numbers conversations are fantastic. “But how will we know what page to look at?” etc.
I’ve given up on native productions for the most part, but for non-standard filetypes where I have more leverage I’ve had some success with the argument that “the best format to review in is the best format to produce in” which only sometimes leads to making placeholder images so we have a place to put the bates stamp.
LikeLike
David Tobin said:
Phil Katz – Excellent.
Just did and it works – can’t wait to tell my attorneys they don’t need to convert word to PDF to redact – ha 🙂
LikeLike
Kashif Husain said:
Hi Craig,
the searchability is really a big loss in that report, OCR can only do so much on probably twice scanned in documents.
Another interesting analysis (although for obvious reasons PDF format biased) of the Mueller report:
https://www.pdfa.org/a-technical-and-cultural-assessment-of-the-mueller-report-pdf/
LikeLiked by 1 person