

Last week, I dug into Cloud Attachments to email, probing the propensity of producing parties’ to shirk collection of linked documents. Here, I want to discuss the versioning concern offered as a justification for non-production and the use of hash duplicate identification to integrate supplementary productions with incomplete prior productions.
Recently on LinkedIn, Very Smart Guy, Rachi Messing, shared this re: cloud attachments,
the biggest issue at hand is not the technical question of how to collect them and search them, but rather what VERSION is the correct one to collect and search.
Is it:
1. The version that existed at the time the email was sent (similar to a point in time capture of a file that is attached to an email the traditional way)
2. The version that was seen the first time the recipient opened it (which may lead to multiple versions required based on the exact timing of multiple recipients opening at varying times)
3. The version that exists the final time a recipient opened it
4. The most recent version in existence
I understand why Rachi might minimize the collection and search issue. He’s knee deep in Microsoft M365 collection. As I noted in my last post, Microsoft makes cloud attachment collection a feature available to its subscribers, so there’s really no excuse for the failure to collect and search cloud attachments in Microsoft M365.
I’d reframe Rachi’s question: Once collected, searched and determined to be responsive, is the possibility that the version of a cloud attachment reviewed differs from the one transmitted a sufficient basis upon which to withhold the attachment from production?
Respecting the versioning concern, I responded to Rachi’s post this way:
The industry would profit from objective analysis of the instance (e.g., percentage) of Cloud attachments modified after transmittal. I expect it will vary from sector to sector, but we would benefit from solid metrics in lieu of the anecdotal accounts that abound. My suspicion is that the instance is modest overall, the majority of Cloud attachments remaining static rather than manifesting as collaborative documents. But my suspicion would readily yield to meaningful measurement. … May I add that the proper response to which version to collect to assess relevance is not ‘none of them,’ which is how many approach the task.
Digging into the versioning issue demands I retread ground on cloud attachments generally.
A “Cloud Attachment” is what Microsoft calls a file transmitted via email in which the sender places the file in a private online repository (e.g., Microsoft OneDrive) and sends a link to the uploaded file to the intended recipients. The more familiar alternative to linking a file as a cloud attachment is embedding the file in the email; accordingly, such “Embedded Attachments” are collected with the email messages for discovery and cloud attachments are collected (downloaded) from OneDrive, ideally when the email is collected for discovery. As a rule-of-thumb, large files tend to be cloud attachments automatically uploaded by virtue of their size. The practice of linking large files as cloud attachments has been commonplace for more than a decade.
Within the Microsoft M365 email environment, searching and collecting email, including its embedded and cloud attachments, is facilitated by a suite of features called Microsoft Purview. Terming any task in eDiscovery “one-click easy” risks oversimplification, but the Purview eDiscovery (Premium “E5”) features are designed to make collection of cloud attachments to M365 email nearly as simple as ticking a box during collection.
When a party using Microsoft M365 email elects to collect (export) a custodian’s email for search, they must decide whether to collect files sent as cloud attachments so they may be searched as part of the message “family,” the term commonly applied to a transmitting message and its attachments. Preserving this family relationship is important because the message tells you who received the attachments and when, where searching the attachments tells you what information was shared. The following screenshot from Microsoft illustrates the box checked to collect cloud attachments. Looks “one-click easy,” right?
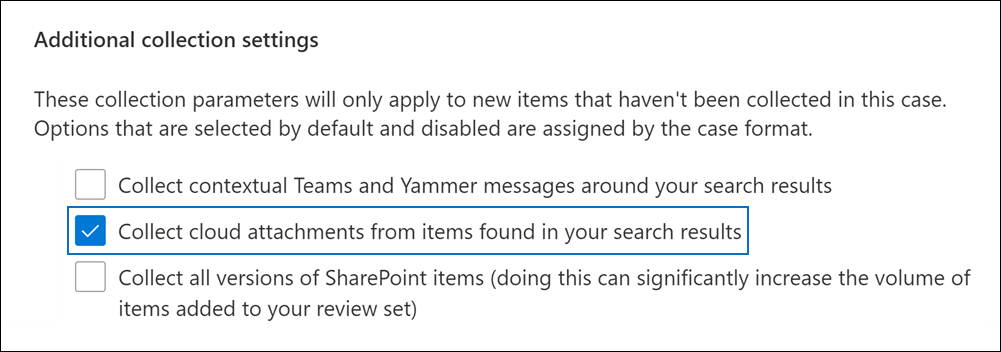
By themselves, the cloud attachment links in a message reveal nothing about the content of the cloud attachments. Sensibly, the target documents must be collected to be assessed and as noted, the reason they are linked is not because they have some different character in terms of their relevance; many times they are linked because they are larger files, so to that extent, they hold a greater volume of potentially relevant information.
Just as it would not have been reasonable in the days of paper discovery to confine a search to documents on your desk but not in your desk, it’s not reasonable to confine a search of email attachments to embedded attachments but not cloud attachments. Both are readily accessible to the custodians of the email using the purpose-built tools Microsoft supplies to its email customers.
Microsoft Purview collects cloud attachments as they exist at the time of collection; so, if the attachment was edited after transmittal, the attachment will reflect those edits. The possibility that a document has been edited is not a new one in discovery; it goes to the document’s admissibility not its discoverability. The relevance of a document for discovery depends on its content and logical unitization, and assessing content demands that it be searched, not ignored on the speculative possibility that it might have changed.
If a cloud attachment were changed after transmittal, those changes are customarily tracked within the document. Accordingly, if a cloud attachment has run the gauntlet of search and review, any lingering suspicion that the document was changed may be resolved by, e.g., production of the version closest in time to transmittal or by the parties meeting and conferring. Again, the possibility that a document has been edited is nothing new; and is merely a possibility. It’s ridiculous to posit that a party may eschew collecting or producing all cloud attachments because some might have been edited.
Cloud attachments are squarely within the ambit of what must be assessed for relevance. The potential for a cloud attachment to be responsive is no less than that of an item transmitted as an embedded attachment. The burden claimed by responding parties grows out of their failure to do what clearly should have been done in the first place; that is, it stems from the responding party’s decision to exclude potentially relevant, accessible documents from being collected and searched.
If you’re smart, Dear Reader, you won’t fail to address cloud attachments explicitly in your proposed ESI Protocols and/or Requests for Production. I can’t make this point too strongly, because you’re not likely to discover that the other side didn’t collect and search cloud attachments until AFTER they make a production, putting you in the unenviable posture of asking for families produced without cloud attachments to be reproduced with cloud attachments. Anytime a Court hears that you are asking for something to be produced a second time in discovery, there’s a risk the Court may be misled by an objection grounded on Federal Rule of Civil Procedure Rule 34(b)(2)(E)(iii), which states that, [a] party need not produce the same electronically stored information in more than one form.” In my mind, “incomplete” and “complete” aren’t what the drafters of the Rule meant by “more than one form,” but be prepared to rebut the claim.
At all events, a party who failed to collect cloud attachments will bewail the need to do it right and may cite as burdensome the challenge of distinguishing items reviewed without cloud transmittals from those requiring review when made whole by the inclusion of cloud attachments.
Once a party collects cloud attachments and transmittals, there are various ways to distinguish between messages updated with cloud attachments and those previously reviewed without cloud attachments. Identifying families previously collected that have grown in size is one approach. Then, by applying a filter, only the attachments of these families would be subjected to supplementary keyword search and review. The emails with cloud attachments that are determined to be responsive and non-privileged would be re-produced as families comprising the transmittal and all attachments (cloud AND embedded). An overlay file may be used to replace items previously produced as incomplete families with complete families. No doubt there are other efficient approaches.
If all transmittal messages were searched and assessed previously (albeit without their cloud attachments), there would not be a need to re-assess those transmittals unless they have become responsive by virtue of a responsive cloud attachment. These “new” families need no de-duplication against prior production because they were not produced previously. I know that sounds peculiar, but I promise it makes sense once you think through the various permutations.
With respect to using hash deduplication, the hash value of a transmittal does not change because you collect a NON-embedded cloud attachment; leastwise not unless you change the way you compute the hash value to incorporate the collected cloud attachment. Hash deduplication of email has always entailed the hashing of selected components of messages because email headers vary. Accordingly, a producing party need compare only the family segments that matter, not the ones that do not. In other words, de-duplicating what has been produced versus new material is a straightforward process for emails (and one that greatly benefits from use of the EDRM MIH). Producing parties do not need to undertake a wholesale re-review of messages; instead, they need to review for the first time those things they should have reviewed from inception.
I’ll close with a question for those who conflate cloud attachments (which reside in private cloud respositories) with hyperlinks to public-facing web resources, objecting that dealing with collecting cloud attachments will require collection of all hyperlinked content. What have you been doing with the hyperlinks in your messages until now? In my experience, loads of us include a variety of hyperlinks in email signature blocks. We’ve done it for years. In my email signature, I hyperlink to my email address, my website and my blog; yet, I’ve never had trouble distinguishing those links from embedded and cloud attachments. The need to integrate cloud attachments in eDiscovery is not a need to chase every hyperlink in an email. Doug Austin does a superb job debunking the “what about hyperlinks” strawman in Assumption One of his thoughtful post, “Five Assumptions About the Issue of Hyperlinked Files as Modern Attachments.”
Bottom Line: If you’re an M365 email user; you need to grab the cloud attachments in your Microsoft repositories. If you’re a GMail user, you need to grab the cloud attachments in your Google Drive respositories. That a custodian might conceivably link to another repository is no reason to fail to collect from M365 and GMail.









