Today, I published my primer on processing. It’s fifty-odd pages on a topic that’s warranted barely a handful of paragraphs anywhere else. I wrote it for the upcoming Georgetown Law Center Advanced E-Discovery Institute and most of the material is brand new, covering a stage of e-discovery–a “black box” stage–where a lot can go quietly wrong. Processing is something hardly anyone thinks about until it blows up.
Today, I published my primer on processing. It’s fifty-odd pages on a topic that’s warranted barely a handful of paragraphs anywhere else. I wrote it for the upcoming Georgetown Law Center Advanced E-Discovery Institute and most of the material is brand new, covering a stage of e-discovery–a “black box” stage–where a lot can go quietly wrong. Processing is something hardly anyone thinks about until it blows up.
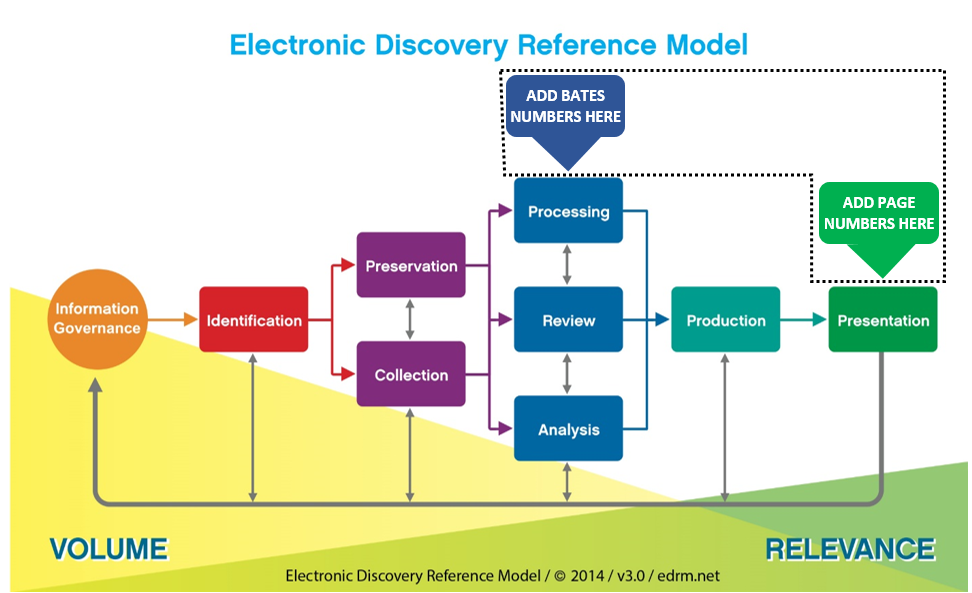
Laying the foundation for a deep dive on processing required I include a crash course on the fundamentals of digitization and encoding. My students at the University of Texas and at the Georgetown Academy have had to study encoding for years because I see it as the best base on which to build competency on the technical side of e-discovery.
The research for the paper confirmed what I’d long suspected about our industry. Despite winsome wrappers, all the leading e-discovery tools are built on a handful of open source and commercial codebases, particularly for the crucial tasks of file identification and text extraction. Nothing evil in that, but it does make you think about cybersecurity and pricing. In the process of delving deeply into processing, I gained greater respect for the software architects, developers and coders who make it all work. It’s complicated, and there are countless ways to run off the rails. That the tools work as well as they do is an improbable achievement. Stilli, there are ingrained perils you need to know, and tradeoffs to be weighed.
Working from so little prior source material, I had to figure a lot out by guess and by gosh. I have no doubt I’ve misunderstood points and could have explained topics more clearly. Please don’t hesitate to weigh in to challenge or correct. Regular readers know I love to hear your thoughts and critiques.
I’ll be talking about processing in an ACEDS/Logikcull webcast tomorrow (Tuesday, November 5, 2019) at 1:00pm EST/10:00am PST. I expect it’s not to late to register.
The milestone of the title is that this is my 200th blog post and it neatly coincides with my 200,000 unique visitor to the blog (actually 200,258, but who’s counting?). When I started blogging here on August 20, 2011, I honestly didn’t know if anyone would stop by. Two hundred thousand kind readers have rung the bell (and that’s excluding the many more spammers turned away). I hope something I wrote along the way gave you some insight or a chuckle. I’m intensely grateful for your attention.
By the way, if you’d like to come to the Georgetown Advanced E-Discovery Institute in Washington, D.C. on November 21-22, 2019, please use my speaker’s discount code to save $100.00. The discount code is BALL (all caps). Hope to see you!