The Texan in me can’t hear the phrase “on the road again” without also hearing Willie Nelson’s nasal voice singing it. But, the life I love IS making music with my friends, if by “music” we mean bringing “aha” moments to lawyers and others interested in e-discovery and forensic technology.
The Texan in me can’t hear the phrase “on the road again” without also hearing Willie Nelson’s nasal voice singing it. But, the life I love IS making music with my friends, if by “music” we mean bringing “aha” moments to lawyers and others interested in e-discovery and forensic technology.
Today, I head to Portland, for the 2018 Preservation Excellence or PREX Conference put on annually by the good folks at Zapproved. It’s a splendid faculty congregated in an always-lovely venue and punctuated by good conversation, fine food and the splendor that is Oregon in September. PREX is always worth the trip; so, if you have the chance to go, by all means, attend.
This year I have a lot to do at PREX. I have the privilege to host a keynote discussion with CNN and The New Yorker magazine legal commentator, Jeffrey Toobin. You can be sure that the U.S. Supreme Court, the Mueller investigation and Brett Kavanaugh’s confirmation hearing will all come up. Toobin is a bestselling author of seven books, including several on the Supreme Court and on the O.J. Simpson murder case and kidnapped heiress Patty Hearst. Talking with Toobin rounds out my opportunity to do Charlie Rose-style conversations with Doris Kearns Goodwin and Nina Totenberg at earlier Zapproved events.
I’ll also moderate a “People’s Court” debate between Brett Tarr and Dan Nichols. Brett is Chief Counsel for E-Discovery and Information Governance at gaming conglomerate Caesars Entertainment, and Dan is a partner with Redgrave LLP, the far-flung corporate e-discovery consultancy. These two really despise each other, so there’s sure to be a lot of eye-gouging and attacks on legitimate parentage. (That’s my story, and I’m sticking to it).
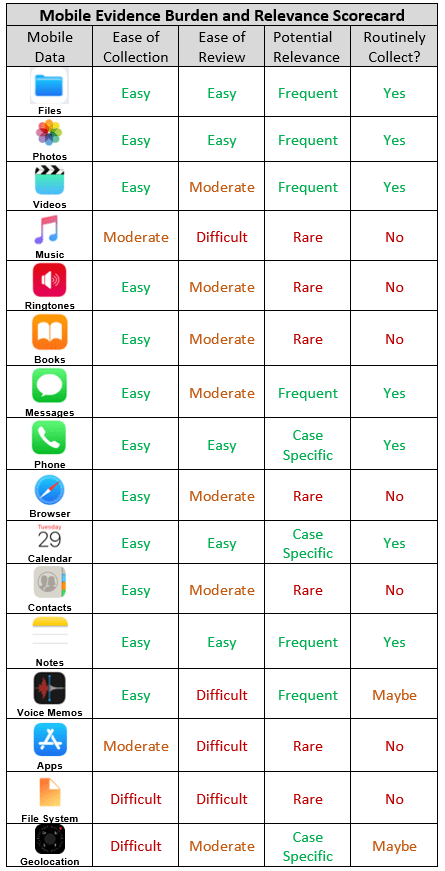
Finally on Wednesday, I’ll be doing a little speaking of my own in a lonely breakout session where we will talk about preserving and discovering evidence on mobile phones. They’ve titled it, OMG, SMS & ESI: Preserving & Collecting from Mobile Devices. The session description reads:
How does one craft a discovery request for text messages? What are the different techniques for preservation, collection and review of mobile data? When does it make sense to complete a full forensic collection on a mobile device? This session will deliver foundational information and practical examples of process and policy management for mobile devices in ediscovery.
if you haven’t yet come to grips with mainstreaming mobile devices into day-to-day e-discovery, know you’re not alone–everyone is struggling, or more likely closing their eyes, hoping mobile will go away. Perhaps we can make some progress together.
PREX September 25 – 27, 2018 | Portland, OR
Then, no-rest-for-the-dreary, I wing to the Windy City of Chicago (so-called NOT due to weather, but for the propensity of its politicians to pontificate at length). I’m heading to the annual Relativity Fest, a stupendous amalgamation of e-discovery education and evangelical tent meeting cum rock concert. If there were the slightest doubt that Relativity dominates the e-discovery review space (and is hungry to gobble up the rest of the EDRM), such foolish doubt will be crushed by the power of Fest.
I enjoy Fest for many reasons, not the least of which is the chance to work with the always-engaging David Horrigan, Relativity’s discovery counsel and legal content director. David is a fine writer, insightful commentator and skilled teacher. Eclipsing that is his distinction as a great guy, someone always fun to be around and adept at eliciting the best from those he hosts.
At Fest, David will moderate a panel I’m on called The Internet of Things from a Legal, Regulatory, and Technical Perspective. I’m fortunate to join Gail Gottehrer, Partner and Co-Chair of the Privacy, Cybersecurity, and Emerging Technology Practice at Akerman, who will give the regulatory perspective, and Ed McAndrew, Partner at Ballard Spahr and former DOJ cybercrime coordinator, who’s charged with the legal point of view. I guess that leaves the technical stuff to me, which is where I’m happiest anyway.
Relativity Fest Sep. 30 – Oct. 3, 2018 | Hilton Chicago
I hope to see you at one or both of these exciting confabs, enjoying two fine faculties in wonderful venues. The joy and value of these events isn’t just what’s planned, but the interactions around and outside of the sessions, too.

 Is there a war on e-discovery? Sounds like a paranoid notion, but the evidence is everywhere. The purpose of discovery is to exchange information bearing on matters in litigation, particularly material tending to prove or disprove the parties’ claims and defenses. The soul of discovery is disclosure of relevant records and communication, limited by privilege and proportionality. So, you’d think the focus of e-discovery would be on where information resides and the forms it takes, on how to preserve it, collect it and produce it. That was what we talked about a decade ago, but, no more.
Is there a war on e-discovery? Sounds like a paranoid notion, but the evidence is everywhere. The purpose of discovery is to exchange information bearing on matters in litigation, particularly material tending to prove or disprove the parties’ claims and defenses. The soul of discovery is disclosure of relevant records and communication, limited by privilege and proportionality. So, you’d think the focus of e-discovery would be on where information resides and the forms it takes, on how to preserve it, collect it and produce it. That was what we talked about a decade ago, but, no more.







 Two-and-a-half years ago, I concluded a
Two-and-a-half years ago, I concluded a  It’s the month for giving thanks, and I’m ever-grateful for the daily e-discovery blog penned by my friend, Doug Austin, for CloudNine. It’s tough to get out a post every business day, and Doug’s done it splendidly for, what, nine years now? Kudos! Doug’s
It’s the month for giving thanks, and I’m ever-grateful for the daily e-discovery blog penned by my friend, Doug Austin, for CloudNine. It’s tough to get out a post every business day, and Doug’s done it splendidly for, what, nine years now? Kudos! Doug’s