 This is a personal post. I’m baring my soul in hopes that colleagues grappling with doubt and transition will know they are not alone. I’m at a point in my career—in my life, really—where I’m obliged to ask, “Who am I if I’m not that guy anymore?”
This is a personal post. I’m baring my soul in hopes that colleagues grappling with doubt and transition will know they are not alone. I’m at a point in my career—in my life, really—where I’m obliged to ask, “Who am I if I’m not that guy anymore?”
At the ILTA conference last month, a colleague lately risen to rarified heights in e-discovery mentioned she’d heard I’d retired. It was a dagger to the heart. I sputtered that, yes, I’d cut back on my insane speaking schedule and was writing less frequently. I was playing more but I hadn’t taken my shingle down.
That’s true, but what I didn’t say was that ofttimes retirement isn’t a choice. It’s thrust upon you when you don’t fight it. And you can’t always fight it. I’m not retired; I’ve just conducted myself as if I were, and chickens have come home to roost. Call it a crisis of confidence. I struggle to feel I’ve got anything to say. After more than 2,000 confident turns at the podium, I feel like a fraud. Do you ever feel that, dear reader? You know, Imposter Syndrome, that feeling that, at any moment, someone might point and say, “you’re not the real deal!”
Let’s put aside the quirks and tics of personality built on shame, insecurity and emotional scarring. We’ve all got that. I think there are three main causes behind my gnawing self-doubt.
The self-serving first is that, having focused on electronic evidence and forensic technology for thirty-odd years, new information must compete for brain space and context against a hoard of old knowledge and experience. I started my professional career when MS-DOS was the dominant operating system and networking meant sharing a daisy wheel printer. That was before e-mail, before the Web and long before mobile. It was possible to be a generalist expert in legal technology, and I was. Back then, you could ask me a question about almost any topic at TechShow and I probably knew the answer. We all did. WordPerfect tips? Sure! The best TSR tools for lawyers? I’ve got that. If you’ve never used WordPerfect or have no clue what “TSR” means, I rest my case.
Expertise demands I acquire new, relevant information and afford it space and ready access among all the once-useful-and-still-occasionally-valuable junk jamming the cerebral storeroom. Did I mention I’m something of a hoarder? It’s a godawful mess in there.
“I know too much” sounds like a Trumpian tweet, and it’s a rotten rationale from anyone. That said, you try keeping track of the forensic artifacts left by Windows XP versus Windows 10, how to crack the latest iOS release and what counts as proof of intentional deprivation under Rule 37(e). I can’t help feeling that life is simpler and confidence in one’s expertise easier to come by when your only context is “now.”
The second contributor to my crisis of confidence is that I’ve lost my laboratory. I no longer work enough matters to feel at the top of my game. It’s not the first time that’s happened. Back when I was trying lawsuits, I spoke frequently about how to create and use demonstrative evidence. I had many examples of visuals I’d built and used in my own cases. They blew folks away. As my practice shifted from first-chair trial lawyer to tech evangelist preaching the gospel of electronic evidence, I no longer built visuals for cases, and my inventory of salient examples grew stale. I lost my laboratory. I stopped making fresh discoveries; so, I stopped teaching demonstrative evidence.
As my engagement in cases has diminished over a few Big Easy years, so, too, has my need to navigate real-world challenges in computer forensics and electronic evidence. I’ve lost my laboratory again and, without fresh challenges, I’m fresh out of insights. I feel rusty, like I’m just an academic.
The third factor is harder to articulate, but it’s a sense that the world has moved on. E-discovery has been “handled.” Forensics is done more by tools than people. Discovery service providers have commoditized and packaged the tasks I once thought lawyers would manage. Civil trials have disappeared, and with them the need to authenticate, offer and challenge electronic evidence. Lawyers no longer do much of what I was helping them to do–or perhaps I wasn’t helping them enough and they’ve found others easier or cheaper to work with.
I don’t discount the unrelenting passage of time either and my aging out (62 last week). Many of my repeat clients have changed careers, retired or died. I did nothing to replace them. Most of the judges who knew me as a go-to guy for computer forensics and e-discovery are off the bench, either by retirement or blown by political winds having nothing to do with their abilities.
Finally, there is competition. I had the field to myself for quite a while. There are more people to go to now. Are they as steeped in e-discovery and computer forensics as I am? Who knows? More to the point, who cares? Lawyers were never especially discriminating when hiring digital forensics and e-discovery experts; less so now. I greatly benefitted from the fact that there weren’t many experts to choose from and amongst lawyers and judges, I enjoyed a high profile. I always strove to be the real deal and supply correct answers; but, if I hadn’t, I’m not convinced anyone would have been the wiser.
I have not retired. I’m still here, and I feel like I have another reinvention in me—a last, best act yet to come. At the same time, I am not so clouded as to miss the signs auguring otherwise. Starting over sounds at once exhilarating and exhausting. I keep wondering: Who am I if I’m not that guy anymore?
I’m fortunate that, even lacking new direction, I enjoy the freedom to move on. No one depends upon me and I have ample savings. As my mother used to say, I just need to handle my money “so I have ten cents left to tip the undertaker.”
I won’t cut it that close and I’ve had a great run (not done, not done); but, I’m worried for those who followed me or found their own way into the field and still need to build their nest eggs. Has it been a hard road? Are they finding it difficult to make a happy living doing what once was so lucrative and exciting? I worry that some followed me down a disappointing path. If you have doubts as I do, please do not despair. Take comfort in schadenfreude. You are not alone, and when we all get to the same place, we can have a wonderful party and talk about it.

 When computer forensics was in its infancy, examiners collected evidence from disks by copying their contents byte-for-byte to matching, sterilized disks, creating archival and working copies called “clones.” Cloning drives was inefficient, expensive and error prone compared to the imaging processes that replaced it. Yet, disk cloning worked for years, and countless cases were made on forensic evidence preserved by cloning and examined on cloned drives.
When computer forensics was in its infancy, examiners collected evidence from disks by copying their contents byte-for-byte to matching, sterilized disks, creating archival and working copies called “clones.” Cloning drives was inefficient, expensive and error prone compared to the imaging processes that replaced it. Yet, disk cloning worked for years, and countless cases were made on forensic evidence preserved by cloning and examined on cloned drives.

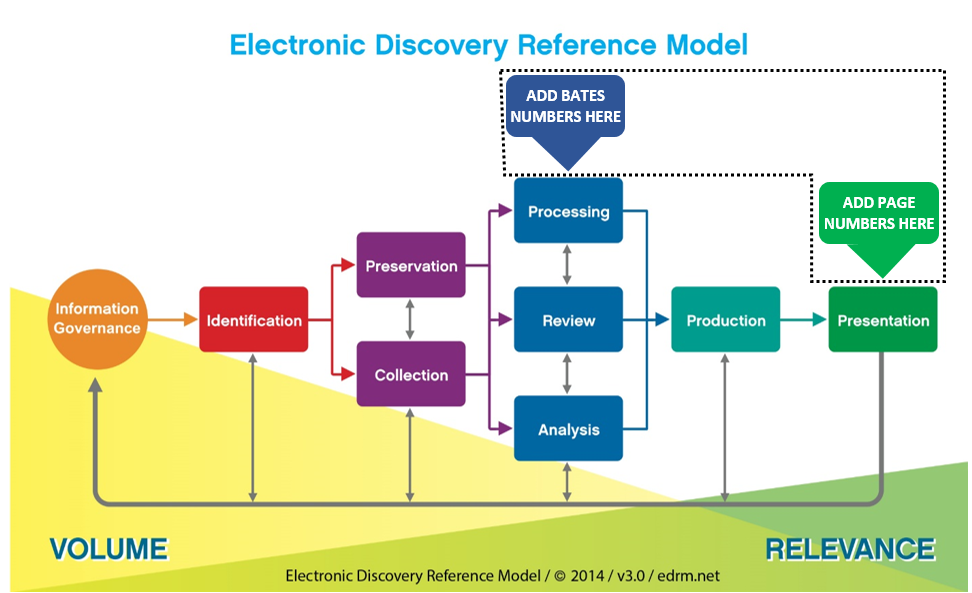








 Checking the mailbag, I received a great question from a recent Georgetown E-Discovery Training Academy attendee. I’m posting it here in hopes my response may be useful to you.
Checking the mailbag, I received a great question from a recent Georgetown E-Discovery Training Academy attendee. I’m posting it here in hopes my response may be useful to you.